Notes for watching YouTube view Deep Dive into LLMs
Deep Dive into LLMs like ChatGPT (2025-02-05)
Pre-traning data
Step1: download and preprocess the internet
Fineweb data in hugging face (44TB)
Url filtering -> text extraction -> lanaguage filter -> filters...
Get raw text at the end of this step.
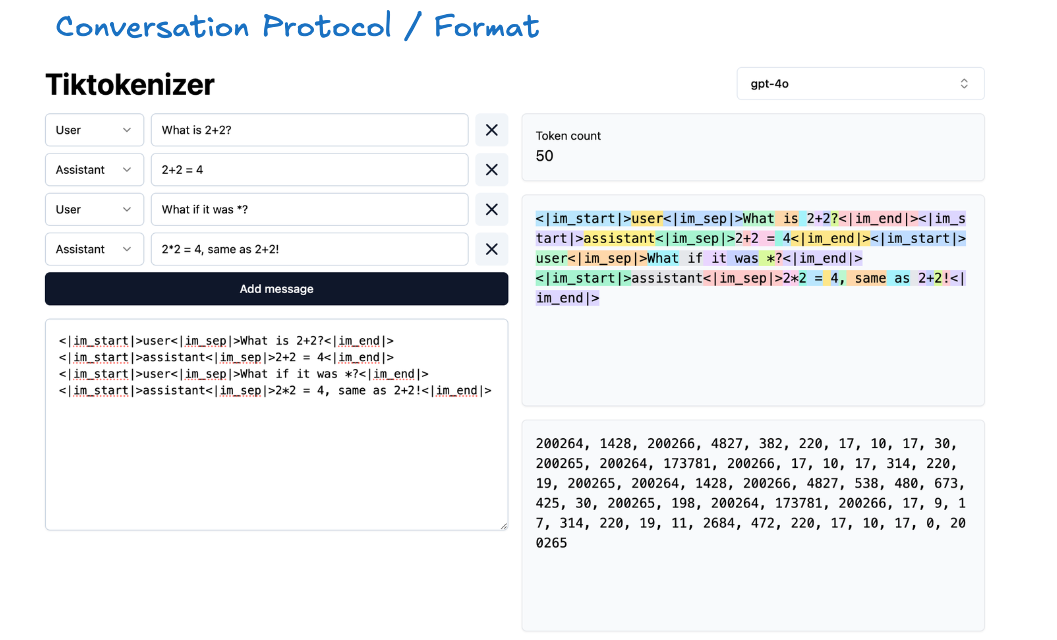
Step2: tokenization
raw text to simbols(tokens)
tiktokenizer.vercel.app
Step 3 Neural network training
Window of tokens
We call a window of tokens "context"
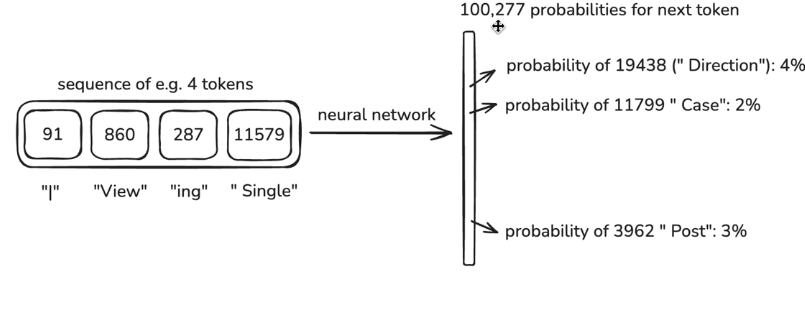
Give the answer, tweak the NN so the probablity of the correct token is higher
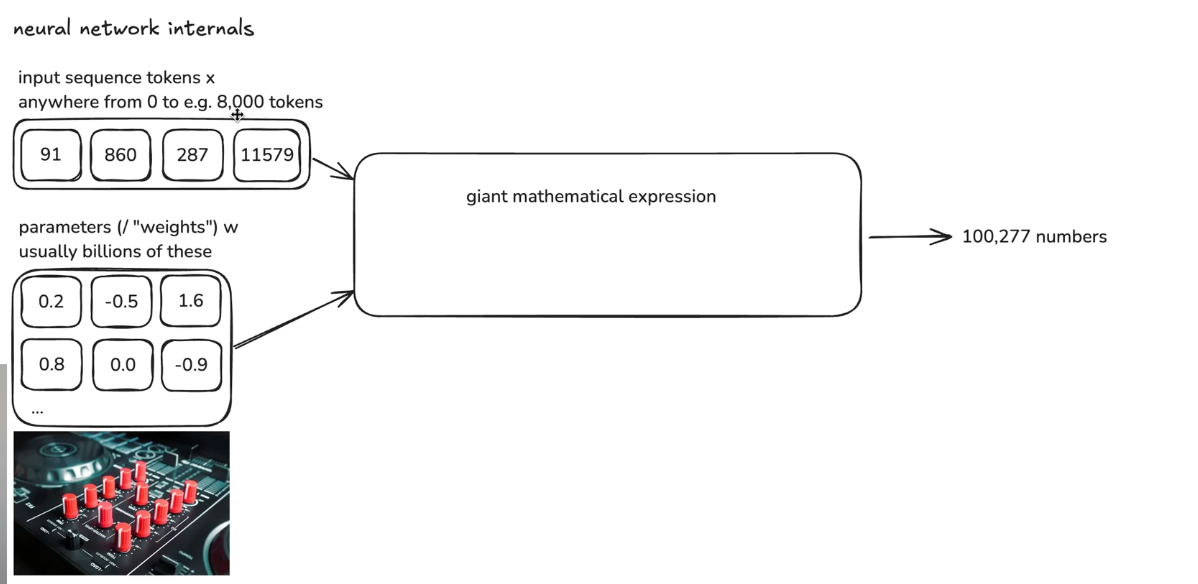
Step4: Inference:
generate data, just predict one token at a time
Post-training data (conversations)

After training from internet documents, then train by human conversations.
This process is much smaller than pre-training
The training is under exact same algrithm just by conversations.
Hallucinations
example: who is Orson Kovacs? LLM has no idea for a fake name.
It's getting better now (updated: 2026-03-08)
How to fix this?

Mitigation1: Use model interrogation to discover model's knowledge and programmatically augment its training dataset with knowledge-based refusals in cases where the model doesn't know
Mitigation2:
Allow the model to search (web search)
Tools
!! Vague recollection vs working memory
knowledge in the parameters == vague recollection
knowledge in the tokens of the context window == working memory
Knowledge of self
hardcode training for self-knowledge
hidden token of self-knowledge(system message )
Models need tokens to think

Left is worse : because it gives answer first, all tokens later are like post-doc. This is more like guess an answer with single token
We need to spread out computation through out the token
Models can't cound
Models are not good with spelling
Models see tokens(text chunks), not letters
Then use tools like code. Updated 2026-03 getting much better now with advanced model
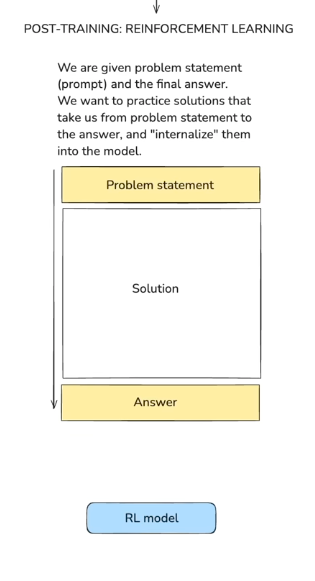
Reinforcement learning
Exposition(background knowledge) == pretraining
Worked problems(problem + demonstrated solution, for imitation) == supervised finetuning
practice problems == reinforcement learning
(prompts to practice, trial & error until you reach the correct answer)
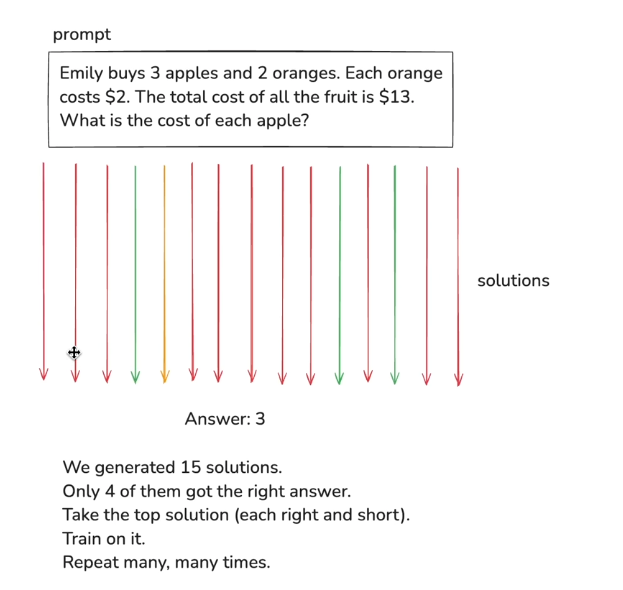
Deepseek R1
RL training is not standard, deepseek found one and open-source
Alpha Go
Reinforcement Learning from Human Feedback (RLHF)
Prompt: write a joke about pelicans
Problem: how do we score them

Upside: we can run RL in arbitrary domains
Downside: lossy simulation of human, might be misleading